
I'm still looking at the rhetoric from the presidential debates, this time focusing on the first general election debate between Hillary Clinton and Donald Trump. I turned the data frame from last week into a corpus, did some pre-processing with the tm package (removing capitalization, punctuation, and stopwords, stemming the words, and then completing stems with most prevalent version of the word in a corpus), turned this into a term-document matrix, and used the wordcloud package to compare the candidates.
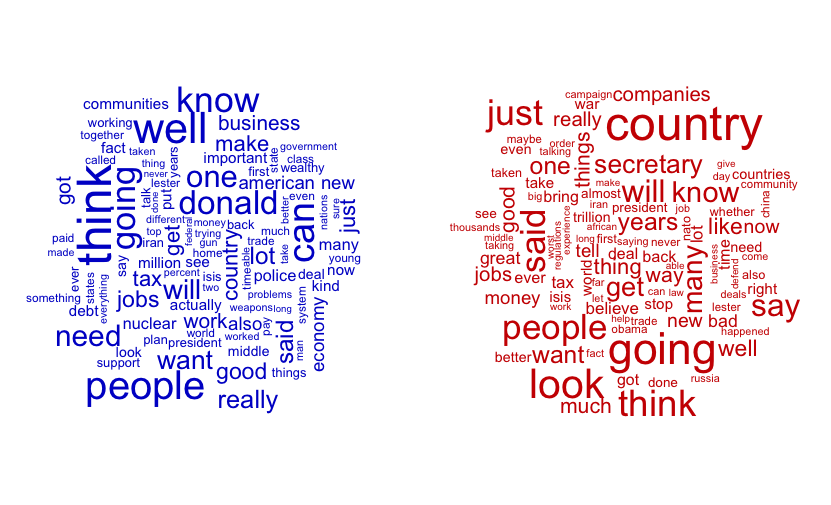
Here are the most frequent words used by Hillary (in blue) and Donald (in red). Honestly, except that they both uttered "think," "people," and "going" quite a bit, these don't reveal much.
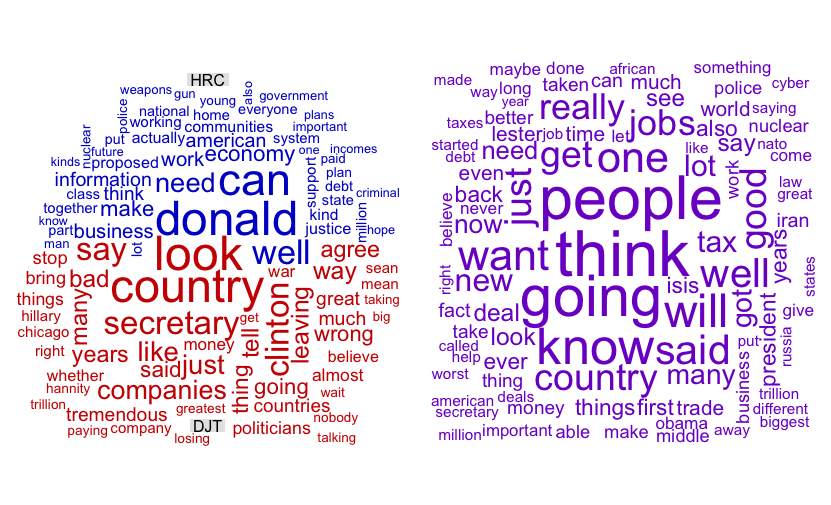
More interesting are the words that discriminate their speech---the comparison cloud on the left---and the words the speakers have in common---the commonality cloud on the right. You clearly see Hillary's "Donald"---the most distinctive word in her collection as she repeatedly and informally referred to her opponent---and Donald's "look" (clearly, saying, "She doesn't have the [presidential] look" was not the only time he used the word; just the most memorable).
There's more to see in and do with this, but I'll stop here. Here's my code, for the interested.
# Make a corpus from the data frame of speech, date, speaker
docvar <- list(content="speech", id="date", speaker="speaker")
myReader <- readTabular(mapping=docvar)
debateCorpus <- Corpus(DataframeSource(candSpeech), readerControl=list(reader=myReader))
# Process the corpus
# Remove capitalization, punctuation, numbers, stopwords, white space; stem words and complete stems
dc <- tm_map(debateCorpus,content_transformer(tolower))
# Function, toSpace, using tm's content_transformer
toSpace <- content_transformer(function(x, pattern)
{return (gsub(pattern, " ", x))})
dc <- tm_map(dc, removeNumbers)
dc <- tm_map(dc, removeWords, c(stopwords("english"), "applause"))
dc <- tm_map(dc, toSpace, "-")
dc <- tm_map(dc, removePunctuation)
dc <- tm_map(dc, stripWhitespace)
dcStem <- tm_map(dc, stemDocument)
# Function, stemCompletion2 (adapted from: http://www.rdatamining.com/)
stemCompletion2 <- function(x, d) {
x <- unlist(strsplit(as.character(x), " "))
x <- x[x != ""]
x <- stemCompletion(x, dictionary=d)
x <- paste(x, sep="", collapse=" ")
PlainTextDocument(stripWhitespace(x))
}
# Apply the function, recreate the corpus, and re-assign metadata
dcComp <- lapply(dcStem, stemCompletion2, dc)
dcComp <- Corpus(VectorSource(dcComp))
meta(dcComp, "id") <- unlist(meta(dc, "id"))
meta(dcComp, "speaker") <- unlist(meta(dc, "speaker"))
# Make a term-document matrix, turn this into a matrix with only the "documents" from the 9/26 debate
dcTDM <- TermDocumentMatrix(dcComp)
dcGen <- as.matrix(dcTDM)
dcGen <- dcGen[,c(10,11)] # HRC and DJT general election terms are the 10th and 11th documents
colnames(dcGen) <- c("HRC", "DJT")
d <- data.frame(word=rownames(dcGen), hrcfreq=dcGen[,1], djtfreq=dcGen[,2])
d <- filter(d, hrcfreq > 0 & djtfreq > 0)
# Wordcloud: frequent words of HRC, DJT
par(mfrow=c(1,2))
wordcloud(d$word, d$hrcfreq, max.words=100, scale=c(3,.25), rot.per=.2, colors="blue3")
wordcloud(d$word, d$djtfreq, max.words=100, scale=c(3,.25), rot.per=.2, colors="red3")
par(mfrow=c(1,1))
# Comparison cloud: words that distinguish HRC, DJT
par(mfrow=c(1,2))
comparison.cloud(dcGen, max.words=75,
scale=c(3,.25), random.order=FALSE,
colors=c("blue3", "red3"), title.size=1)
# Commonality cloud: words that are shared by HRC, DJT
commonality.cloud(dcGen, max.words=75,
random.order=FALSE, colors="purple3")
par(mfrow=c(1,1))
Michele Claibourn
Director, Research Data Services
University of Virginia Library
October 0, 2016
For questions or clarifications regarding this article, contact statlab@virginia.edu.
View the entire collection of UVA Library StatLab articles, or learn how to cite.