
I'm teaching a Text as Data short course (using R) right now, and as a card-carrying political scientist, I couldn't resist using the ongoing campaign as an example (this was, in part, a way of handling my own anxiety about last Monday's debate---this is what I was doing while watching). So here goes...
In preparation for the first general election debate of the season, I scraped the transcripts of the primary debates from The American Presidency Project's website using Hadley Wickham's rvest package. It went something like this:
# Load the source page
source.page %>%
html_nodes("a") %>% # get the CSS nodes
html_attr("href") # extract the URLs
url1 %>%
html_nodes("td.docdate") %>% # get the CSS nodes
html_text() # extract the link text
# select just obs that reflect 2016 debates and add party: should amend this select and label more automatically... later
url1 <- url1[c(41:55,57:62)]
link1 <- link1[c(3,6:14,16:20, 22:27)]
debates <- data.frame(links=link1, urls=url1, stringsAsFactors=FALSE)
debates$party <- c("general", rep("democrat", 9), rep("republican", 11))
# Get each transcript and give it a filename
for(i in seq(nrow(debates))) {
text <- read_html(debates$urls[i]) %>% # load the page
html_nodes(".displaytext") %>% # isloate the text
html_text() # get the text
# Create the file name
filename <- paste0(debates$party[i], "-", debates$links[i], ".txt")
# and send the output to the appropriately named file
sink(file = filename) %>% # open file to write
cat(text) # put the contents of "text" in the file
sink() # close the file
}
I wanted documents that reflected the speech acts of individual candidates. The transcript reads in as one blob, so I needed to read each in, extract the speaker, split by the speaker, and create an object that retained each speaker. Really, I just wanted to see Clinton and Trump. Once I was able to do this, Clay turned it into a function for me (thanks, Clay!).
dem.files <- DirSource(pattern="democrat") # create a list of files to read; only those with democrat in filename
rep.files <- DirSource(pattern="republican")
getLines <- function(x, person){
text <- readLines(x) # read in the file
id <- unlist(str_extract_all(text, "[A-Z]+:")) # get the speaker
Lines <- unlist(strsplit(text, "[A-Z]+:"))[-1] # split by speaker (and get rid of a pesky empty line)
Lines[id %in% person] # retain speech by relevant speaker
}
ClintonLines <- lapply(dem.files$filelist, getLines, person = "CLINTON:")
TrumpLines <- lapply(rep.files$filelist, getLines, person = "TRUMP:")
I turned these into data frames with the speech, date, and speaker and started playing! (If you really want to see the rest of the code, let me know.)
First, I used the ngram library to capture all tri-grams (every contiguous sequence of three words) in each candidate's speech, and I used that that generate a probabilistic sequence for Trump and Clinton ("babbling" in ngram's parlance). I removed the identifying names/biographical details, but bet you can still guess which is which! The babbled text suggests very different styles:
- "And I know [name redacted] feels badly about it. And I think that there are people that truly don't need it, and there are few people anywhere, anywhere that would have known those names. I think he negotiated one of the most talented people. They go to Yale. They go to Princeton. They come from another country and they're immediately sent out. I am all in favor of Libya? I never discussed that subject. I was in favor of Libya? I never discussed that subject. I was in South Carolina, we had 12,000 people. It set up in about four days. We have galvanized and we've created a movement. A lot of times — a lot of the world leaders that this country negotiated that deal. But very important. Not only a disgrace, it's a disgrace and an embarrassment. But very important, who are we fighting ISIS in Syria? Let them fight each other and pick up the remnants. I would talk to him. I hit other things. I talked about illegals immigration. It wouldn't even be talking."
- "And I've said, if the big banks don't play by the rules, I have been evening the odds for people that are left out and left behind. And I know very well that we have to do more to help small businesses, they are the source of two thirds of our jobs and we have to try to move together to have a place in the Middle East. They want American soldiers on the ground in Syria and Iraq.I support special forces. I support trainers. I support the air campaign. And I think that is an area we can get back on their feet economically. And I just want to say this Senator. There is broad consensus, 92 percent in the most recently poll of Americans want common sense gun safety measures. And I applaud his record in Maryland. I just wish he wouldn't misrepresent mine. Every day, I think about all ..."
Not bad (at least, it made me laugh; during Monday's debate, I kept babbling the primary debate speech listening for similarities)!
I also used the koRpus library to estimate the "readability," or complexity, of each candidate's speech. The readability score is a function of (a) the number of words per sentence and (b) the number of syllables per word (this is the Flesch-Kincaid measure).
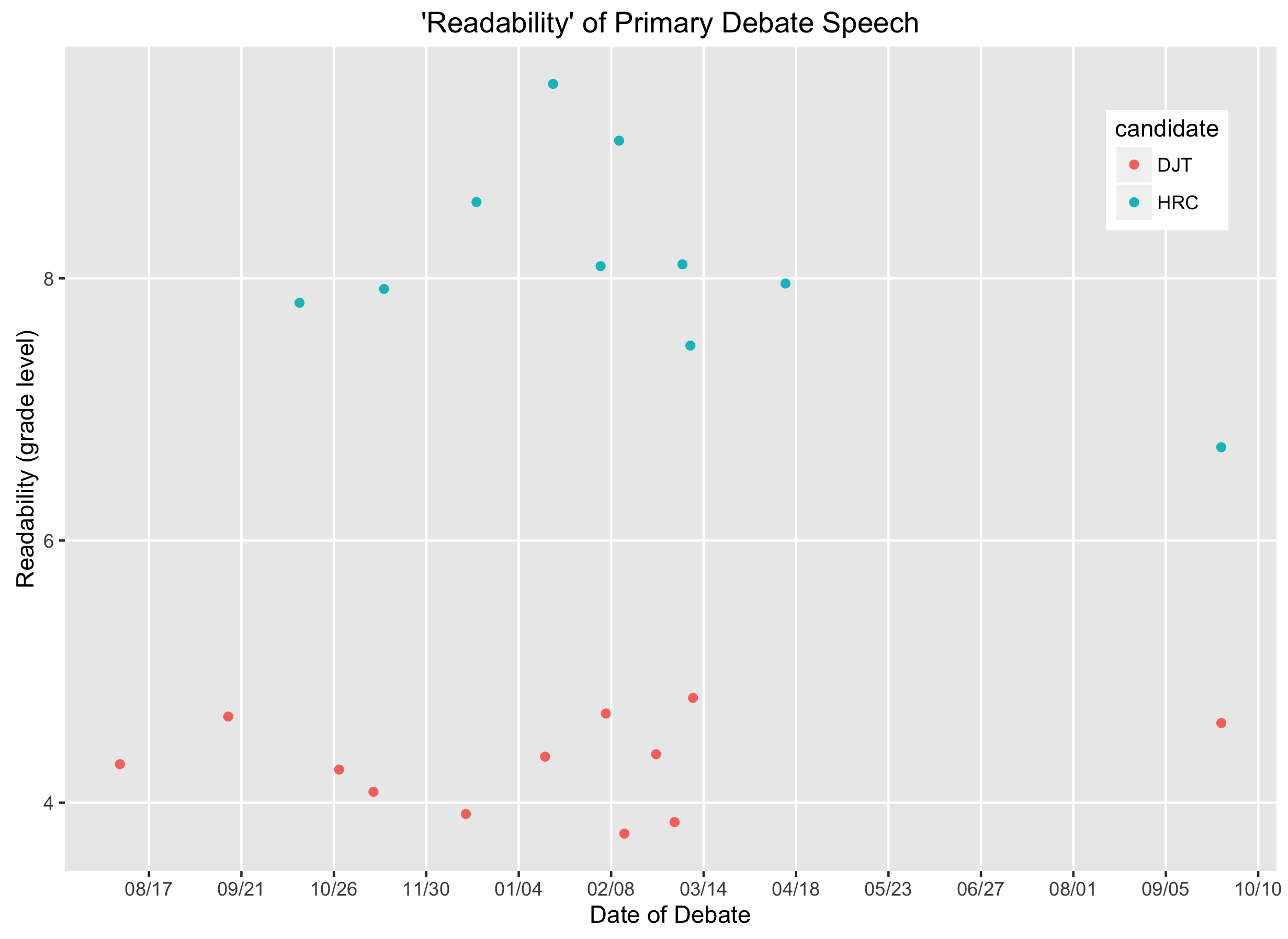
So, wow! That's some separation right there. The figure tells me there's a difference in the complexity of each candidate's debate speech, but not why. The primary debate context was, after all, pretty different for Trump---who shared the stage with multitudes---and Clinton. Trump, though, does seem to struggle with complete sentences. If the transcript treats this disjointedness as separate, and thus shorter, sentences, this measure will be reduced. On the other hand, as a colleague said, maybe Trump is easier to understand...
I'm most curious about the difference in Clinton's primary debate speech and her first general election debate. Did she speak more simply? Did Trump pull her down? Or, my guess, is it just a function of the more numerous interruptions? Every time the transcript switches between Trump and Clinton, the pre-interruption utterance and post-interruption utterance will be recorded as separate sentences even if it's a continued comment.
The text analysis alone can't answer this question directly---we'd need to actually read some of the transcripts to understand the why (which is pretty much always true, in my experience). And that's likely to generate some additional analysis... so stay tuned.
Michele Claibourn
Director, Research Data Services
University of Virginia Library
September 28, 2016
For questions or clarifications regarding this article, contact statlab@virginia.edu.
View the entire collection of UVA Library StatLab articles, or learn how to cite.