
The QQ plot, or quantile-quantile plot, is a graphical tool to help us assess if a set of data plausibly came from some theoretical distribution such as a normal or exponential. For example, if we run a statistical analysis that assumes our residuals are normally distributed, we can use a normal QQ plot to check that assumption. It’s just a visual check, not an air-tight proof, so it is somewhat subjective. But it allows us to see at-a-glance if our assumption is plausible, and if not, how the assumption is violated and what data points contribute to the violation.
A QQ plot is a scatterplot created by plotting two sets of quantiles against one another. If both sets of quantiles came from the same distribution, we should see the points forming a line that’s roughly straight. Here’s an example of a normal QQ plot when both sets of quantiles truly come from normal distributions.
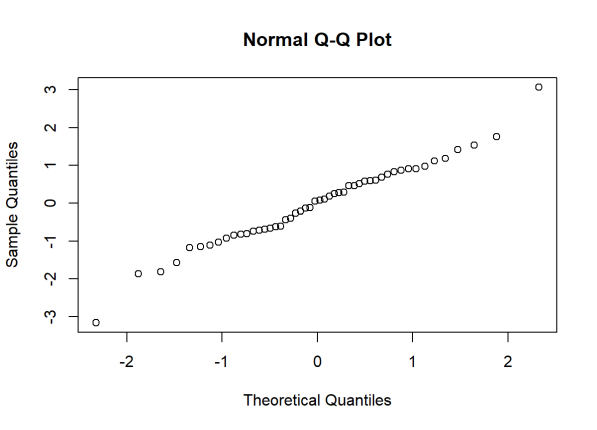
Now what are “quantiles”? These are often referred to as “percentiles.” These are points in your data below which a certain proportion of your data fall. For example, imagine the classic bell-curve standard normal distribution with a mean of 0. The 0.5 quantile, or 50th percentile, is 0. Half the data lie below 0. That’s the peak of the hump in the curve. The 0.95 quantile, or 95th percentile, is about 1.64. 95 percent of the data lie below 1.64. The following R code generates the quantiles for a standard normal distribution from 0.01 to 0.99 by increments of 0.01:
qnorm(seq(0.01,0.99,0.01))
We can also randomly generate data from a standard normal distribution and then find the quantiles. Here we generate a sample of size 200 and find the quantiles for 0.01 to 0.99 using the quantile() function:
quantile(rnorm(200),probs = seq(0.01,0.99,0.01))
So we see that quantiles are basically just your data sorted in ascending order, with various data points labelled as being the point below which a certain proportion of the data fall. However it’s worth noting there are many ways to calculate quantiles. In fact, the quantile() function in R offers 9 different quantile algorithms! See help(quantile) for more information.
QQ plots take your sample data, sort it in ascending order, and then plot them versus quantiles calculated from a theoretical distribution. The number of quantiles is selected to match the size of your sample data. While normal QQ plots are the ones most often used in practice due to so many statistical methods assuming normality, QQ plots can actually be created for any distribution.
In R, there are two functions to create QQ plots: qqnorm() and qqplot().
qqnorm() creates a normal QQ plot. You give it a vector of data, and R plots the data in sorted order versus quantiles from a standard normal distribution. For example, consider the trees data set that comes with R. It provides measurements of the girth, height, and volume of timber in 31 felled black cherry trees. One of the variables is Height. Can we assume our sample of heights comes from a population that is normally distributed?
qqnorm(trees$Height)
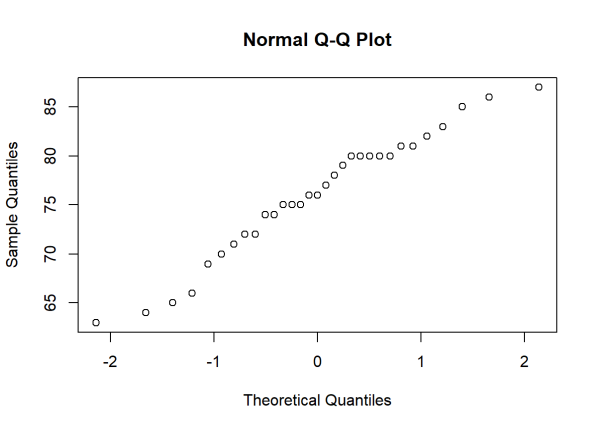
That appears to be a fairly safe assumption. The points seem to fall about a straight line. Notice the x-axis plots the theoretical quantiles. Those are the quantiles from the standard normal distribution with mean 0 and standard deviation 1.
The qqplot() function allows you to create a QQ plot for any distribution. Unlike the qqnorm() function, you have to provide two arguments: the first set of data and the second set of data. Let’s look at the randu data that come with R. It’s a data frame that contains 3 columns of random numbers on the interval (0,1). Random numbers should be uniformly distributed. Therefore we can check this assumption by creating a QQ plot of the sorted random numbers versus quantiles from a theoretical uniform (0,1) distribution. Here we create a QQ plot for the first column of numbers, called x:
y <- qunif(ppoints(length(randu$x)))
qqplot(randu$x,y)
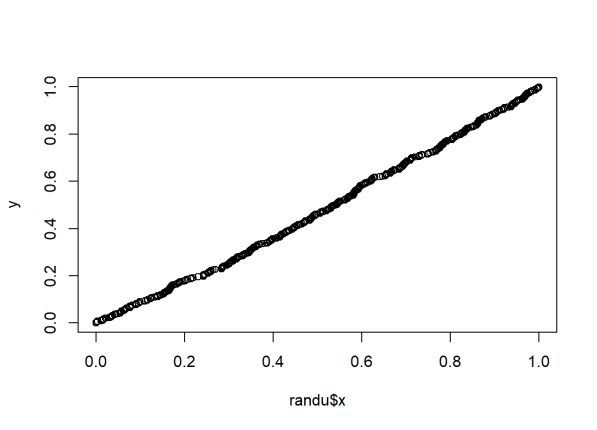
The ppoints() function generates a given number of probabilities or proportions. We wanted the same number of values in randu$x, so we gave it the argument length(randu$x), which returns 400. The qunif() function then returns 400 quantiles from a uniform distribution for the 400 proportions. We save that to y and then plot y versus randu$x in the qqplot() function. Again, we see points falling along a straight line in the QQ plot, which provide strong evidence that these numbers are uniformly distributed.
What about when points don’t fall on a straight line? What can we infer about our data? To help us answer this, let’s generate data from one distribution and plot against the quantiles of another. First we plot a distribution that’s skewed right, a chi-square distribution with 3 degrees of freedom, against a normal distribution.
qqplot(qnorm(ppoints(30)), qchisq(ppoints(30),df=3))
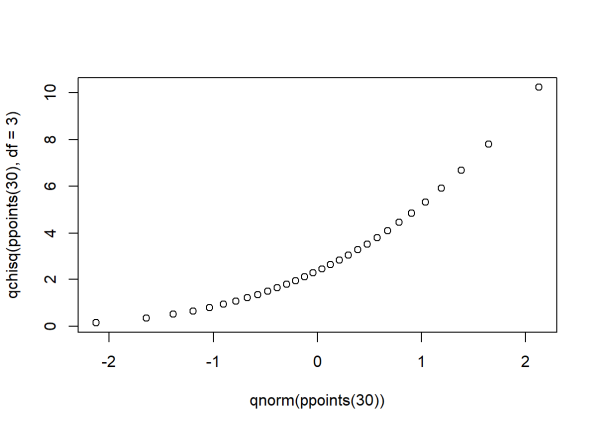
Notice the points form a curve instead of a straight line. Normal QQ plots that look like this usually mean your sample data are skewed.
Next we plot a distribution with “heavy tails” versus a normal distribution:
qqplot(qnorm(ppoints(30)), qcauchy(ppoints(30)))
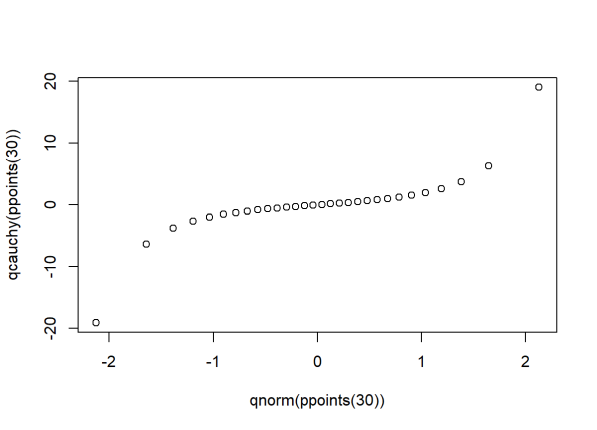
Notice the points fall along a line in the middle of the graph, but curve off in the extremities. Normal QQ plots that exhibit this behavior usually mean your data have more extreme values than would be expected if they truly came from a normal distribution.
R session details
Analyses were conducted using the R Statistical language (version 4.5.1; R Core Team, 2025) on Windows 11 x64 (build 26100)
References
- Hogg R and Tanis E. (2006). Probability and Statistical Inference. Prentice Hall. Chapter 3.
- R Core Team (2025). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/.
Clay Ford
Statistical Research Consultant
University of Virginia Library
August 26, 2015
For questions or clarifications regarding this article, contact statlab@virginia.edu.
View the entire collection of UVA Library StatLab articles, or learn how to cite.