
In the forums and Q&A sections of websites like Stack Overflow, GitHub, and forum.posit.co, there is a volunteer force of data-science detectives, code consultants, and error-fighting emissaries ready to offer assistance to programmers who find themselves staring down unhappy code that’s resisting placation. Getting a clear, helpful response on these forums—or from any resource—depends in large part on asking a clear, helpful question. Help the helpers by including a reprex (a reproducible example) when asking a code question. A quality reprex is:
- Self-contained: Everything needed to recreate the issue at hand should be contained in the reprex
- Minimal: Use small and/or built-in data (e.g., mtcars), and strip away extraneous code
- Runnable: A simple copy-paste should be all that’s needed to run the reprex, and running it shouldn’t generate errors except for those that the reprex is intended to exemplify
- Optional: Don’t force people to run the code in order to understand the issue; include the relevant output/errors as part of the reprex (in a way that doesn’t disrupt the code’s runnability)
- Reproducible: Use seeds for random processes
- Nonintrusive: Don’t mess with other people’s settings and computer environments (but if you do, [a] be obvious about it and [b] put things back the way they were)
The point of accompanying a question or bug report with a reprex is to present an issue in a concise, repeatable way. Without a reprex, it can be impossible to (efficiently) resolve a problem. Consider this example of how not to structure a query:
“I need to convert a character string representing Dec. 1, 2020, into a date object, but when I run the as_date() function in R, the output has the year, month, and day all wrong. Any advice?”
There’s no clear starting point for addressing this question. Is the literal character string “Dec. 1, 2020”? Is it “120120”? Could it be “2020-12-01”? And how are the year, month, and day all wrong? Further, unless someone responding to the question happens to recognize that as_date() is from the lubridate package, they’re likely to run into entirely avoidable friction as they try to recreate and address the issue.
Resolving the hiccup would be much easier if the code causing the problem was presented in a runnable form, if the necessary packages were made explicit, and if the output was visible from the start (sometimes, the fix is apparent from inspection alone). The reprex package from Jenny Bryan and others at Posit provides a user-friendly toolkit for generating well-formatted, sanity-saving reprexes for all sorts of R code problems. At base, it’s this simple: Copy code to the clipboard, then run reprex::reprex().
A basic reprex() use case
Say that I encounter the following situation: I have a data frame with a column of user IDs and a couple columns of miscellaneous data (see below). The IDs currently all have an superfluous “\\userid” tag at the end that I’d like to remove.
set.seed(90)
IDer <- function(...) {paste0(paste0(sample(c(sample(letters, 9), 0:9), 8), collapse = ''), '\\userid')}
df <- data.frame(id = replicate(100, IDer()),
some_data = round(rnorm(100), digits = 3),
other_data = round(runif(100), digits = 3))
head(df)
id some_data other_data
1 1rw953qb\\userid -0.835 0.716
2 g4u267t3\\userid -0.503 0.150
3 h8204n3t\\userid 0.838 0.017
4 e5iu2t18\\userid 0.011 0.250
5 609ab258\\userid 0.876 0.452
6 lnr0qo68\\userid 1.578 0.551
To clean up the ID strings, I plan to use regular expressions. Using the stringi package, I try to extract the character group in each row that is followed by “\\userid” (I attempt this using a positive lookahead—that’s the ?= in the regex pattern below1). So, if an ID is listed as “abc123\\userid”, I want to pull out “abc123”.
library(stringi)
df$id_clean <- stri_extract(df$id, regex = '(.*)(?=\\userid)')
Error in stri_extract_first_regex(str, regex, ...):
Unrecognized backslash escape sequence in pattern. (U_REGEX_BAD_ESCAPE_SEQUENCE, context=`(.*)(?=\userid)`)
This code generates an error. It’s clear that the issue has something to do with the backslashes, but the search pattern (“\\userid”) would seem to be the one I should to use to extract the IDs. I play around for a bit to try and figure out what’s wrecking the code, but nothing works. Blood pressure rises; curse words are uttered; coffee is made rather furiously; etc. The time comes to turn to an online forum—or even just a friend via email—for assistance.
Question-asking etiquette dictates that I should include a reprex. But how best to go about making one? The reprex should be minimal, so instead of sharing the whole data set, I can use just one ID as an example. And to be self-contained, the reprex should explicitly attach the stringi package. The following code is a good starting point:
library(stringi)
id <- 'abc123\\userid'
stri_extract(id, regex = '(.*)(?=\\userid)')
But this isn’t a complete reprex yet: It’d be useful to actually include the error that the code generates as part of the reprex. That way, no one trying to help resolve the issue is forced to run the code to see what occurs. Including the error, however, shouldn’t disrupt the code lines—the reprex must still be runnable.
This is where the reprex package comes in. With the package attached, a user can generate a reprex by copying code to the clipboard and running reprex(). reprex() will take the code on the clipboard and run it in a fresh R environment (via callr::r() and rmarkdown::render()). The output of this process will reveal whether the reprex is indeed self-contained and runnable, and whether it successfully captures the issue that the user intends it to. The reprex itself is saved to the user’s clipboard for easy pasting; it contains the code and the output/errors/etc., with the latter formatted as comments so as not to interfere with the code’s runnability. By default, the reprex is formatted as GitHub-Flavored Markdown. (There are other formatting options as well, including commented R code; see below under Further features.) The reprex sent to the clipboard for the code chunk above is:
``` r
library(stringi)
id <- 'abc123\\userid'
stri_extract(id, regex = '(.*)(?=\\userid)')
#> Error in stri_extract_first_regex(str, regex, ...):
#> Unrecognized backslash escape sequence in pattern. (U_REGEX_BAD_ESCAPE_SEQUENCE, context=`(.*)(?=\userid)`)
```
<sup>Created on 2021-06-01 by the [reprex package](https://reprex.tidyverse.org) (v2.0.0)</sup>
This can be pasted directly into a post on a website that renders Markdown (like Github, Stack Overflow, or forum.posit.co). Once shared, others can easily see the code and its output, as well as copy and run the code to exactly recreate the error in question. The rendered reprex—i.e., how it would appear if you pasted the Markdown into a post/comment—will also pop up in the RStudio Viewer:
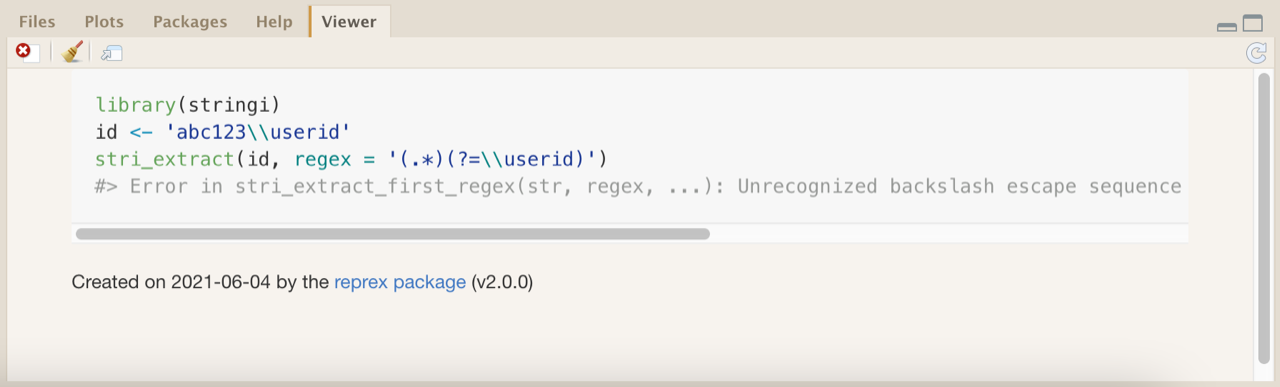
(You can stop reprex() from displaying the rendered reprex in the RStudio Viewer by adding html_preview = F as an argument in reprex(). The “Created on…” banner can be suppressed by adding advertise = F.)
In the case above, reprex() ran without any issues (other than the intended error), so it’s clear that the reprex is self-contained. It’s lightweight and free of extraneous content, and it includes code and output (and the output doesn’t interfere with the code’s runnability). If the code was not self-contained, running reprex() would not recreate the intended error. For example, say that I forget to explicitly attach the stringi package and run reprex() with just the following copied to the clipboard:
id <- 'abc123\\userid'
stri_extract(id, regex = '(.*)(?=\\userid)')
In this case, the following results:
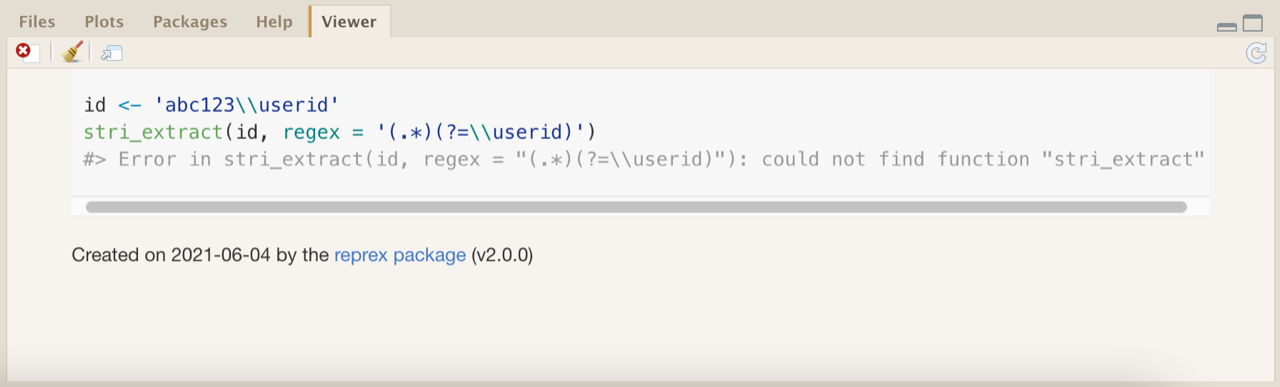
Here, the error exemplified in the reprex is a result of not attaching stringi; it’s not a product of backslash issue that I’m trying to resolve. It’s apparent, then, that the reprex isn’t yet ready to go—I need to add library(stringi) or use stringi::stri_extract(). In a sense, the point of reprex() is to fail early and often: If the code included in the reprex isn’t self-contained and runnable, reprex() will continue to break until the only issue left is the one that the programmer intends to exemplify.
Alternative ways of running reprex()
Instead of copying code to the clipboard and then running reprex(), a user can directly include code as an argument in the function call:
reprex(sum(1, 10))
Multiline code can be delivered to reprex() using curly brackets:
reprex({
x <- 1
y <- 10
sum(x, y)
})
Images in reprexes
The package makes sharing plots and images as part of reprexes easy. A figure generated as part of a reprex will be uploaded to imgur, and a link will be included in the formatted reprex that’s sent to the user’s clipboard. For example, say that I want to inquire on a forum about how to italicize the x- and y-axis labels in the plot below, so I run reprex() on the following code:
library(ggplot2)
ggplot(mtcars, aes(x = hp, y = mpg)) +
geom_point()
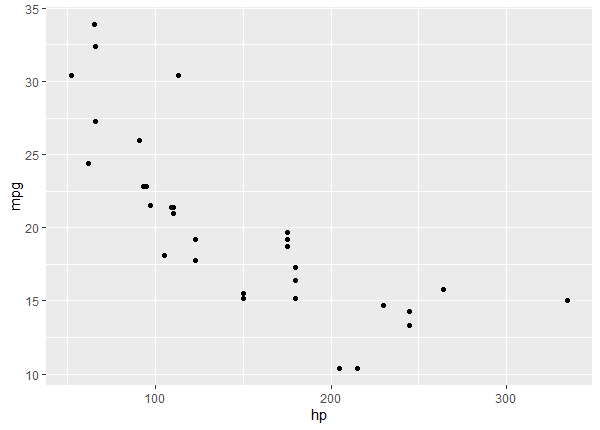
The Markdown-formatted reprex sent to the clipboard in response is:
``` r
library(ggplot2)
ggplot(mtcars, aes(x = hp, y = mpg)) +
geom_point()
```

<sup>Created on 2021-06-01 by the [reprex package](https://reprex.tidyverse.org) (v2.0.0)</sup>
When this Markdown is posted on a site like Stack Overflow, the linked image will be rendered as part of it. This feature of reprex() involves actively uploading content to imgur, so it’s important to be sensitive to what’s being uploaded. Don’t upload figures with private information. Once something is up on imgur, it can be hard to remove. Find an alternative to posting the question “How can I italicize my Social Security number in the subtitle of this plot?”
Further features
At times, it may be relevant to include information about the version of R and/or the package versions you’re using. For example, the release of R 4.1.0 in May 2021 saw the introduction of a base pipe, |>, similar to magrittr’s %>%. This could plausibly cause backward-compatibility issues. A user can include session info (R version, OS, attached/loaded packages, and more) by adding si = T as an argument in reprex().
You can also request that a reprex be formatted to suit the particular style proclivities of a given medium by supplying a venue argument in reprex(). The default argument is "gh" (Github-Flavored Markdown). Alternatives include "so" (Stack Overflow Markdown) and "ds" (Discourse), both of which are currently (as of June 2021) aliases for "gh". There’s also venue = "r", which outputs a reprex as commented R code for easy copy-pasting into emails and R scripts, as well as "slack", "html" and "rtf". (You can bypass the venue argument by calling reprex_<venue>() directly, e.g., reprex_slack().)
Behind the scenes, reprex() doesn’t just copy the formatted reprex to the user’s clipboard and render it in the RStudio Viewer; it also saves the reprex in a directory (generally, as an .md file and an .R file). By default, this is done in a temporary directory that can usually be ignored (use tempdir() to see the path). If desired, a user can declare an alternative location to save the reprex. Using reprex(wd = '.') will drop the reprex file(s) in the current working directory. This can be useful if, say, it’s simply impossible to create a reprex for a given issue without referencing local files.
Repretiquette
A reprex should be nonintrusive. Ensuring this requires attending to a few points of politesse:
- If you create files as part of a reprex, include code to delete them (
file.remove()) - If you change options, change them back at the end of the reprex
- E.g., don’t just run
par(mfrow = c(2,2))on its own; instead, run:opt <- par(mfrow = c(2,2))code code codepar(opt)
- E.g., don’t just run
- Don’t overwrite existing functions (leave
read.csv()as is) - If you attach packages with
library(), consider detaching them at the end of the reprex (withdetach()), especially if they mask common functions; or, call functions from packages using thepkg::fnc()approach instead oflibrary(pkg)
No magic bullets
The reprex package does a lot of heavy lifting, but creating a quality reprex still requires thoughtfulness: reprex() can’t tell you that your example code contains distracting fluff; it can’t tell you not to overwrite base R’s mean() with your own bespoke function for generating insults; it can’t tell you not to use a confusing.Object_NAMING_system_9.9. Be ruthless in simplifying and cleaning reprex code. The denizens of online help forums and Q&A sections do a lot to help their coding communities, and all of us who benefit from their pro bono work can make their efforts easier by accompanying questions with code that doesn’t require a slog of exhausting edits or secondhand study.
By the way: The issue with the regex in stri_extract() earlier? R interprets a single “\” as an escape character, not a literal backslash. To reference a single backslash, I’d need to escape the escape (“\\”). To reference two backslashes in stri_extract(), I’d need to escape the escape twice (“\\\\”). The code should have been: stri_extract(df$id, regex = '(.*)(?=\\\\userid)'). Alternatively, using regex = '(.*)(?=\\W)' achieves the same result.
R session details
The analysis was done using the R Statistical language (v4.5.2; R Core Team, 2025) on Windows 11 x64, using the packages reprex (v2.1.1) and stringi (v1.8.7).
References
- Bryan J, Hester J, Robinson D, Wickham H, Dervieux C (2024). reprex: Prepare Reproducible Example Code via the Clipboard. doi:10.32614/CRAN.package.reprex https://doi.org/10.32614/CRAN.package.reprex, R package version 2.1.1, https://CRAN.R-project.org/package=reprex.
- Gagolewski M (2022). “stringi: Fast and portable character string processing in R.” Journal of Statistical Software, 103(2), 1-59. doi:10.18637/jss.v103.i02 https://doi.org/10.18637/jss.v103.i02.
- R Core Team (2025). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/.
Jacob Goldstein-Greenwood
StatLab Associate
University of Virginia Library
June 4, 2021
For questions or clarifications regarding this article, contact statlab@virginia.edu.
View the entire collection of UVA Library StatLab articles, or learn how to cite.