
When it comes to modeling counts (i.e., whole numbers greater than or equal to 0), we often start with Poisson regression. This is a generalized linear model where a response is assumed to have a Poisson distribution conditional on a weighted sum of predictors. For example, we might model the number of documented concussions to NFL quarterbacks as a function of snaps played and the total years experience of his offensive line. However, one potential drawback of Poisson regression is that it may not accurately describe the variability of the counts.
A Poisson distribution is parameterized by \(\lambda\), which is both its mean and variance. While convenient to remember, it's not often realistic. A distribution of counts will usually have a variance that's not equal to its mean. When we see this happen with data that we assume (or hope) is Poisson distributed, we say we have under- or overdispersion, depending on if the variance is smaller or larger than the mean. Performing Poisson regression on count data that exhibits this behavior results in a model that doesn't fit well.
One approach that addresses this issue is Negative Binomial Regression. The negative binomial distribution, like the Poisson distribution, describes the probabilities of the occurrence of whole numbers greater than or equal to 0. Unlike the Poisson distribution, the variance and the mean are not equivalent. This suggests it might serve as a useful approximation for modeling counts with variability different from its mean. The variance of a negative binomial distribution is a function of its mean and has an additional parameter, k, called the dispersion parameter. Say our count is random variable Y from a negative binomial distribution, then the variance of Y is $$ var(Y) = \mu + \mu^{2}/k $$
As the dispersion parameter gets larger and larger, the variance converges to the same value as the mean, and the negative binomial converges to a Poisson distribution.
To illustrate the negative binomial distribution, let's work with some data from the book, Categorical Data Analysis, by Alan Agresti (2002). The data are presented in Table 13.6 in section 13.4.3. The data are from a survey of 1308 people in which they were asked how many homicide victims they know (1990 General Social Survey, National Opinion Research Center). The variables are resp, the number of victims the respondent knows, and race, the race of the respondent (black or white). Does race help explain how many homicide victims a person knows? The data first needs to be entered into R:
# Table 13.6
# Agresti, p. 561
black <- c(119,16,12,7,3,2,0)
white <- c(1070,60,14,4,0,0,1)
resp <- c(rep(0:6,times=black), rep(0:6,times=white))
race <- factor(c(rep("black", sum(black)), rep("white", sum(white))),
levels = c("white","black"))
victim <- data.frame(resp, race)
Before we get to modeling, let's explore the data. First we notice most respondents are white:
table(race)
race
white black
1149 159
Blacks have a higher mean count than whites:
with(victim, tapply(resp, race, mean))
white black
0.09225413 0.52201258
For each race the sample variance is roughly double the mean. It appears we have overdispersion.
with(victim, tapply(resp, race, var))
white black
0.1552448 1.1498288
Finally we look at the distribution of the counts by race.
table(resp, race)
race
resp white black
0 1070 119
1 60 16
2 14 12
3 4 7
4 0 3
5 0 2
6 1 0
On to model fitting. First we try Poisson regression using the glm() function and show a portion of the summary output.
# Poisson model
pGLM <- glm(resp ~ race, data=victim, family = poisson)
summary(pGLM)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.38321 0.09713 -24.54 <2e-16 ***
raceblack 1.73314 0.14657 11.82 <2e-16 ***
Race is very significant. It appears blacks are much more likely to know someone who was a victim of a homicide. But what does the coefficient 1.73 mean? In this simple model with one dichotomous predictor, it is the difference in log expected counts. If we exponentiate the coefficient we get a ratio of sample means:
exp(coef(pGLM)[2])
raceblack
5.658419
# same thing
mean(victim$resp[victim$race=="black"])/mean(victim$resp[victim$race=="white"])
[1] 5.658419
In fact if we make a prediction with this model and exponentiate the results, we get the sample means:
exp(predict(pGLM, newdata = data.frame(race=c("white","black"))))
1 2
0.09225413 0.52201258
# same thing
with(victim, tapply(resp, race, mean))
white black
0.09225413 0.52201258
This says the count of known victims for whites is distributed as a Poisson with mean and variance equal to 0.09, while the count of known victims for blacks is distributed as a Poisson with mean and variance equal to 0.52. We already know from our exploratory analysis that the observed variances were much larger, so we shouldn't be too pleased with the model's estimated variances. If we examine the fitted counts, we'll see even more evidence for the lack of fit:
# fitted counts for Poisson GLM:
fmeans <- exp(predict(pGLM, newdata = data.frame(race = c("white","black"))))
fmeans
1 2
0.09225413 0.52201258
fittedW <- dpois(0:6,lambda = fmeans[1]) * sum(victim$race=="white")
fittedB <- dpois(0:6,lambda = fmeans[2]) * sum(victim$race=="black")
data.frame(Response=0:6,BlackObs=black, BlackFit=round(fittedB,1),
WhiteObs=white, WhiteFit=round(fittedW,1))
Response BlackObs BlackFit WhiteObs WhiteFit
1 0 119 94.3 1070 1047.7
2 1 16 49.2 60 96.7
3 2 12 12.9 14 4.5
4 3 7 2.2 4 0.1
5 4 3 0.3 0 0.0
6 5 2 0.0 0 0.0
7 6 0 0.0 1 0.0
Above we first saved the predicted means into an object called fmeans. We then generated fitted counts by using the dpois() function along with the estimated means to predict the probability of getting counts 0 through 6. We then multiplied those probabilities by the number of respondents to obtain fitted counts. Finally we combined everything into a data frame to easily compare observed and fitted values. Two of the more dramatic things to note is that we're underfitting the 0 counts and overfitting the 1 counts.
We can use a rootogram to visualize the fit of a count regression model. The rootogram() function in the topmodels package makes this easy.
# Need to install from R-Forge instead of CRAN
# install.packages("topmodels", repos = "https://R-Forge.R-project.org")
topmodels::rootogram(pGLM)
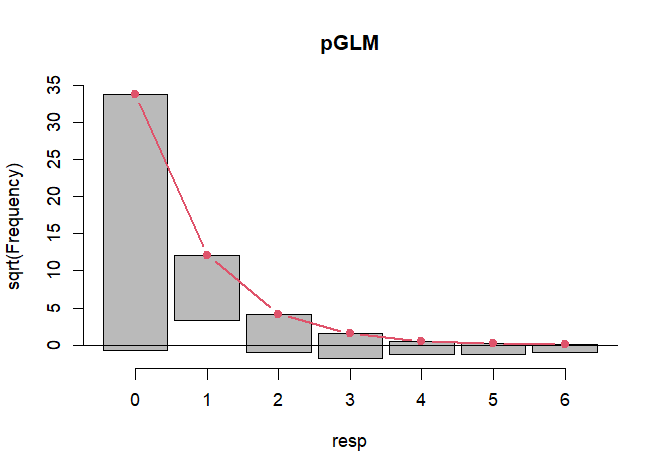
The red curved line is the theoretical Poisson fit. "Hanging" from each point on the red line is a bar, the height of which represents the difference between expected and observed counts. A bar hanging below 0 indicates underfitting. A bar hanging above 0 indicates overfitting. The counts have been transformed with a square root transformation to prevent smaller counts from getting obscured and overwhelmed by larger counts. We see a great deal of underfitting for counts 2 and higher and massive overfitting for the 1 count.
Now let's try fitting a negative binomial model. We noticed the variability of the counts were larger for both races. It would appear that the negative binomial distribution would better approximate the distribution of the counts.
To fit a negative binomial model in R we turn to the glm.nb() function in the MASS package (a package that comes installed with R). Again we only show part of the summary output:
# Fit a negative binomial model
library(MASS)
nbGLM <- glm.nb(resp ~ race, data=victim)
summary(nbGLM)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.3832 0.1172 -20.335 < 2e-16 ***
raceblack 1.7331 0.2385 7.268 3.66e-13 ***
Theta: 0.2023
First notice the coefficients are the same as before. Once again we can exponentiate the race coefficient to get a ratio of sample means and make predictions to get the original sample means.
# fitted counts for Negative Binomial GLM:
fmeans <- exp(predict(pGLM, newdata = data.frame(race = c("white","black"))))
fmeans # same as pGLM
1 2
0.09225413 0.52201258
But notice the standard error for the race coefficient is larger, indicating more uncertainty in our estimate (0.24 versus 0.15). This makes sense given the observed variability in our counts. Also notice the estimate of Theta. That is our dispersion parameter. We can access it directly from our model object as follows:
nbGLM$theta
[1] 0.2023119
And we can use it to get estimated variances for the counts:
fmeans + fmeans^2 * (1/nbGLM$theta)
1 2
0.134322 1.868928
These are much closer to the observed variances than those given by the Poisson model.
Once again we visualize the fit using a rootogram:
topmodels::rootogram(nbGLM)
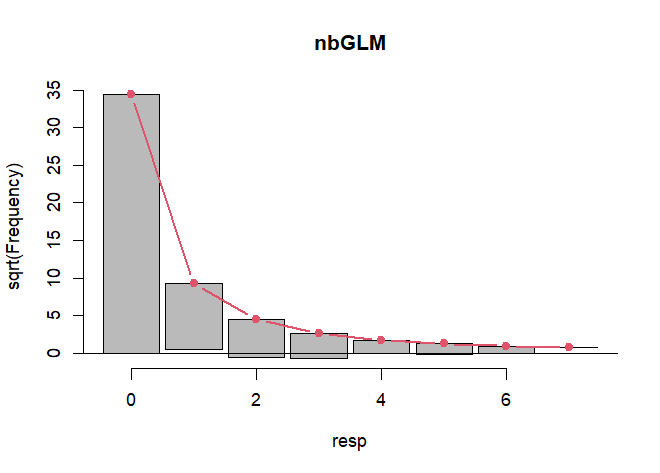
This looks much better than the Poisson model rootogram. There is slight underfitting/overfitting for counts 1 through 3, but otherwise it looks pretty good.
R session details
The analysis was done using the R Statistical language (v4.5.2; R Core Team, 2025) on Windows 11 x64, using the packages MASS (v7.3.65) and topmodels (v0.3.0).
References
- Agresti, A. (2002), Categorical Data Analysis, Wiley.
- Kleiber, C. & Zeileis, A. (2016): Visualizing Count Data Regressions Using Rootograms, The American Statistician, DOI: 10.1080/00031305.2016.1173590
- R Core Team (2023). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. .
- Venables, W. N. & Ripley, B. D. (2002) Modern Applied Statistics with S. Fourth Edition. Springer, New York. ISBN 0-387-95457-0
- Zeileis A, Lang MN, Stauffer R (2024). topmodels: Infrastructure for Forecasting and Assessment of Probabilistic Models. R package version 0.3-0/r1791, https://R-Forge.R-project.org/projects/topmodels/.
Clay Ford
Statistical Research Consultant
University of Virginia Library
May 5, 2016
Updated May 17, 2023
Updated May 24, 2024
For questions or clarifications regarding this article, contact statlab@virginia.edu.
View the entire collection of UVA Library StatLab articles, or learn how to cite.